前言
本文会对Fidder这款工具的一些重要功能,进行详细讲解,带大家进入Fidder的世界,本文会让你明白,Fidder不仅是一个抓包分析工具,也是一个请求发送工具,更加可以当作为Mock Server使用,而且可以写断点,让我们一起进入Fidder的世界吧!
A.工具简介
一.基本模块划分
1.第一块区域是设置菜单,这个前面3篇都有介绍
2.第二块区域是一些快捷菜单,可以点下快捷功能键3.第三块左边是抓捕的请求会话列表,每一个请求就是一个会话4.第四块右边上方区域是request请求的详细信息,可以查看Headers、Cookies、Raw、JSON等5.第五块右边下方区域就是response信息,可以查看服务端返回的json数据或其它信息
6.第六块区域左下角黑色的那块小地方,虽然很不起眼,容易被忽略掉,这地方是命令行模式,可以输入简单的指令如:cls,执行清屏的作用等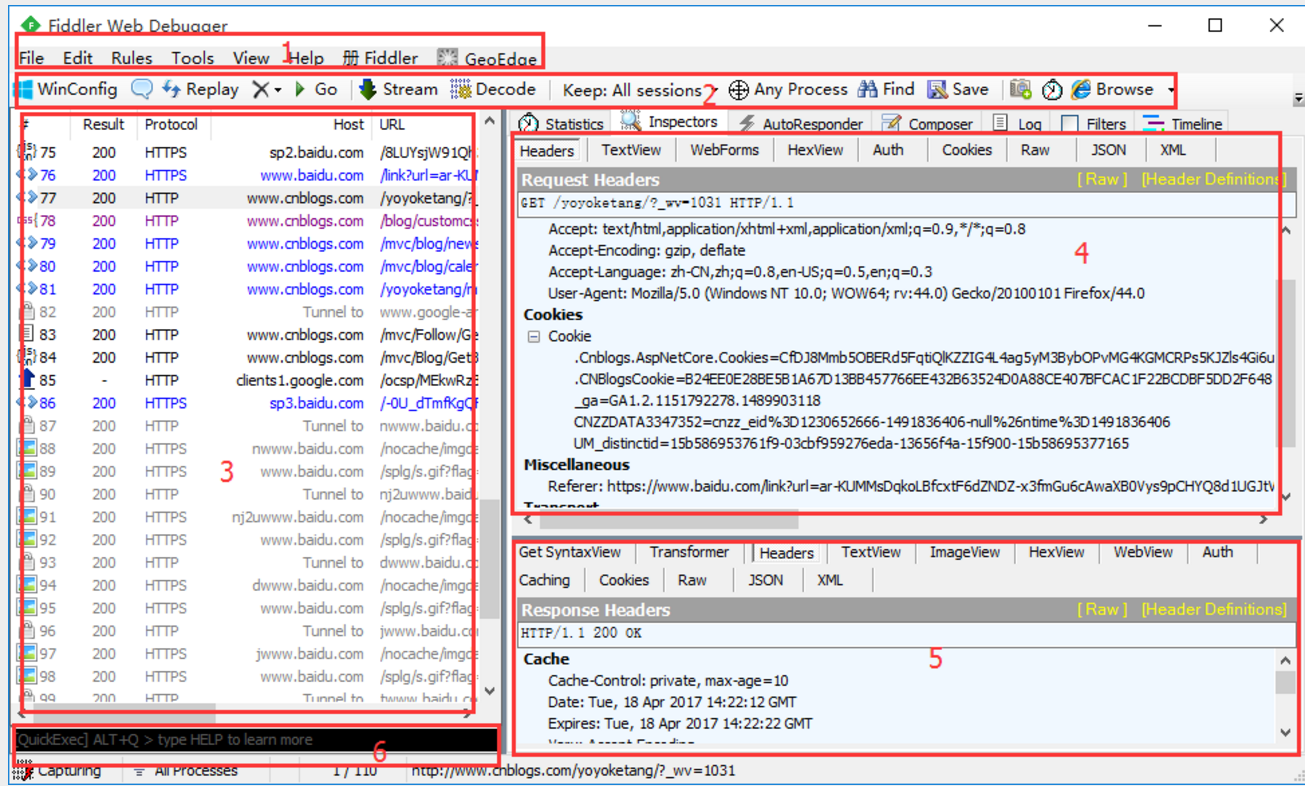
二、会话框
1.会话框主要查看请求的一些请求的一些基本信息,如# 、result、protocol、host、url、body、 caching、content-type、process
2、#:会话框列表最左侧,#号这一栏是代表这个请求大概是什么内容,<>这个符号就是我们一般要测试的请求与响应的类型。
3.result:这里是服务器返回的代码,如
--200,请求ok;2xx一般是服务器接受成功了并处理--3xx,重定向相关--4xx,404最常见的的就是找不到服务器,一般是请求地址有问题--5xx,这个一般是服务器本身的错误4.protocol:这个是协议类型,如http、https5.host:主机地址或域名6.url:请求的路径7.body:该条请求产生的数据大小8.caching:缓存相关9.content-type:连接类型
10.process:客户端类型
三、Request 和Response
1.Request是客户端发出去的数据,Response是服务端返回过来的数据,这两块区域功能差不多
2.headers:请求头,这里包含client、cookies、transport等
3.webfroms:请求参数信息表格展示,更直观。可以直接该区域的参数4.Auth:授权相关,如果显示如下两行,说明不需要授权,可以不用关注(这个目前很少见了)No Proxy-Authorization Header is present.No Authorization Header is present.5.cookies:查看cookie详情6.raw:查看一个完整请求的内容,可以直接复制7.json:查看json数据8.xml:查看xml文件的信息四、decode解码
1.如果response的TextView区域出现乱码情况,可以直接点下方黄色区域解码
2.也可以选中上方快捷菜单decode,这样后面的请求都会自动解码了

B.会话保存
为什么要保存会话呢?举个很简单的场景,你在上海测试某个功能接口的时候,发现了一个BUG,而开发这个接口的开发人员是北京的一家合作公司。你这时候给对方开发提bug,如何显得专业一点,能让对方心服口服的接受这个BUG呢?如果只是截图的话,不是很方便,因为要截好几个地方还描述不清楚,不如简单粗暴一点把整个会话保存起来,发给对方。
一、保存为文本
1.以博客园登录为例,抓到登录的请求会话2.点左上角File>Save>Selected Sessions>as Text,保存到电脑上就是文本格式的
3.文本格式的可以直接打开,结果如下图

二、几种保存方式
1.save-All Sessions :保存所有的会话,saz文件2.save-Selected Session:保存选中的会话--in ArchiveZIP :保存为saz文件
--as Text :以txt文件形式保存整个会话包括Request和Response--as Text (Headers only) :仅保存头部3.Request:保存请求--Entir Request:保存整个请求信息(headers和body)--Request Body:只保存请求body部分4.Response:保存返回--Entir Response:保存整个返回信息(headers和body)--Response Body:只保存返回body部分--and Open as Local File:保存Response信息,并打开文件三、乱码问题(decode)
1.打开博客园首页:http://www.cnblogs.com/yoyoketang/,保存之后查看,会发现返回的是乱码
2.遇到这种情况,主要是需要解码,用前面学到的decode方法

3.点击箭头区域后,重新保存就没乱码了。
4.还有一个最简单办法就是选中上图会话框上的decode按钮,这样就自动解码了。四、保存与导入全部会话
1.我们可以打开fiddler,操作完博客园后,选中save>All Sessions,保存全部会话2.保存后,在fiddler打开也很方便,直接把刚才保存的会话按住拽进来就可以了
3.也可以选择File>Load Archive导入这个文件

五、Repaly
1.导入请求后,可以选中某个请求,点击Repaly按钮,重新发请求2.也可以ctrl+a全部选中后,点Repaly按钮,一次性批量请求

这样保存会话和replay功能其实就是相当于录制和回放了
C.自定义会话框
一、添加会话框菜单
1.点会话框菜单(箭头位置),右键弹出选项菜单
2.选择Customize columns选项,Collection选项选择Miscellaneous

3.Field Name选择:RequestMethod


4.点Add按钮即可添加成功

二、隐藏会话菜单
1.选择需要隐藏的菜单,右键。选择Hide this column
2.隐藏后也可以让隐藏的菜单显示出来:Ensure all columns are visble

三、调整会话框菜单顺序
1.如果需要调整会话框菜单顺序,如:Content-Type菜单按住后往前移动,就能调整了
四、会话排序
1.点击会话框上的菜单,就能对会话列表排序了,如点body菜单
2.点完后上面有个上箭头(正序),或者下箭头(倒叙)。但是不能取消,取消的话关掉fiddler后重新打开就行了。
D.断点(bpu)
这个功能本来不打算分享给大家的,但是这个功能的确是一个强大的功能,用的好你就可以走上人生巅峰,迎娶白富美,用的不好,很容易成为黑客或者会有更加严重的后果!但是后面想了一下,你想成为什么,谁都拦不住,反而想学知识的人,会觉得这个功能是神器!话扯得有点远,言归正传。什么是断点?还有断点有什么用呢?我们一一为大家揭晓!
一. 断点
1. 断点的作用
举个例子,以登录中的账号为例,限制了必须用手机号注册,这样登录自动限制了登录账号为11位,同时前端和后端同时判断输入的账号是不是为11位,如果我们要测试后端有没有对大于11位或者小于11位做出判断,很显然,前端只能输入等于11位的。如果输入超过11位或者少于11位,前端就不发送请求去请求后端。所以我们需要抓到接口,修改请求参数,绕过前端验证,发送一个大于或小于11位的数给后端,验证后端功能是否OK。
2.fidder中断点的体现
- Fiddler设置断点,可以修改HTTP请求头信息,如修改Cookie,User-Agent等
- 可以修改请求数据,突破表单限制,提交任意数字,如充值最大100,可以修改成10000
- 拦截响应数据,修改响应体,如修改服务端返回的页面数据
二、断点的两种方式
1.before response:这个是打在request请求的时候,未到达服务器之前
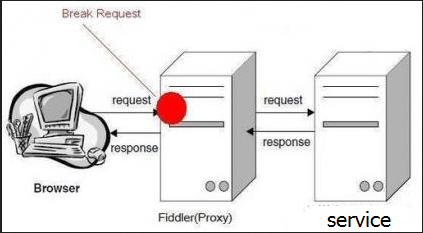
2.after response:也就是服务器响应之后,在Fiddler将响应传回给客户端之前

三、全局断点
1.全局断点就是中断fiddler捕获的所有请求,先设置下,点击rules-> automatic breakpoint ->before requests
2.选中before requests选项后,打开博客园首页:http://www.cnblogs.com/yoyoketang/,看到如下T的标识,说明断点成功

3.打完断点后,会发现所有的请求都无法发出去了,这时候,点下Go按钮,就能走下一步了

4.找到需要修改的请求后,选中该条会话,右侧打开WebFroms,这时候里面的参数都是可以修改的了

5.修改之后点Run to Completion就能提交了,于是就成功修改了请求参数了
6.打全局断点的话,是无法正常上网的,需要清除断点:rules-> automatic breakpoint ->disabled
四、单个断点
已经知道了某个接口的请求地址,这时候只需要针对这一条请求打断点调试,在命令行中输入指令就可以了
请求前断点(before response): bpu1. 论坛登录接口:https://passport.cnblogs.com/user/signin2. 命令行输入:bpu https://passport.cnblogs.com/user/signin 回车
3.请求登录接口的时候,就会只拦截登录这个接口了,此时可以修改任意请求参数
4.取消断点,在命令行输入: bpu 回车就可以了
响应后断点(after requests): bpafter 1. 论坛登录接口:https://passport.cnblogs.com/user/signin2. 在命令行输入:bpafter https://passport.cnblogs.com/user/signin 回车3.登录博客园,会发现已经拦截到登录后服务器返回的数据了,此时可以修改任意返回数据
4.取消断点,在命令行输入: bpafter 回车就可以了 五、拦截来自某个网站所有请求 1.在命令行输入:bpu www.cnblogs.com2.打开博客园任意网页,发现都被拦截到了
3.打开博客园其他网站,其它网站可以正常请求 4.说明只拦截了来自部落论坛(www.cnblogs.com)的请求 5.清除输入bpu回车即可E. get和post请求
一、get请求
1.打开fiddler工具,然后浏览器输入博客首页地址:http://www.cnblogs.com/yoyoketang/
2.点开右侧Inspectors下的Headers区域,查看Request Headers
3.Request Headers区域里面的就是请求头信息,可以看到打开博客园首页的是get请求

二、post请求
1.打开登录首页:https://passport.cnblogs.com/user/signin
2.输入账号和密码登录成功后,查看fiddler抓包的请求头信息,可以看出是post请求
三、如何找出需要的请求
1.打开fiddler后,左边会话框区域刷刷刷的很多请求,那么如何有效的找出自己需要的请求呢?2.首先第一步:清屏(cls),在左下角命令行输入cls,清空屏幕(清屏也可以使用快捷键Ctrl+X)
3.第二步在浏览器输入url地址的时候,记住这个地址,如打开博客首页:http://www.cnblogs.com/yoyoketang/,在点击登录按钮的时候,不要做多余的操作了,然后查看fiddler会话框,这时候有好几个请求。
4.如下图,红色框框这个地方就是host地址,红色圈圈地方就是url的路径(yoyoketang),也就是博客首页的地址了,那这个请求就是博客首页的请求了。

F. get请求(url详解)
一、url详解
1.url就是我们平常打开百度在地址栏输入的:https://www.baidu.com,如下图,这个是最简单的url地址,打开的是百度的主页
2.再看一个稍微复杂一点的url,在百度输入框输入:上海悠悠博客园

3.查看url地址栏,对比之前的百度首页url地址,后面多了很多参数。当然最主要的参数是/s?wd=上海悠悠博客园(后面的一大串可以暂时忽略)。
4.那么问题来了,这些参数有什么作用呢?可以做个简单的对比,在地址栏分别输入:https://www.baidu.com
https://www.baidu.com/s?wd=上海悠悠博客园对比打开的页面有什么不一样,现在知道作用了吧,也就是说这个多的"/s?wd=上海悠悠博客园"就是搜索的结果页面 二、url解析1.以"https://www.baidu.com/s?wd=上海悠悠博客园"这个url请求的抓包为例
2.那么一个完整的url地址,基本格式如下:
https://host:port/path?xxx=aaa&ooo=bbb--http/https:这个是协议类型,如图中所示--host:服务器的IP地址或者域名,如图中2所示
--port:HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如:192.168.3.111:8080,这里的8080就是端口--path:访问资源的路径,如图中3所示/s (图中3是把path和请求参数放一起了)--?:url里面的?这个符号是个分割线,用来区分问号前面的是path,问号后面的是参数--url-params:问号后面的是请求参数,格式:xxx=aaa,如图4区域就是请求参数--&:多个参数用&符号连接 三、请求参数(params)1.在url里面请求参数一般叫params,但是我们在fiddler抓包工具看到的参数是:QueryString
2.QueryString是像服务端提交的参数,其实跟params是一个意思,每个参数对应的都有name和value值3.多个参数情况如下:
四、UrlEncode编码
1.如果url地址的参数带有中文的,一般在url里面会是这样的,如第二点里的wd=%E4%B8%8A%E6%B5%B7%E6%...像看到%E4这种编码的就是经过url编码过的,需要解码就能看到是什么中文了2.用urlencode在线编码/解码工具,地址:http://tool.chinaz.com/tools/urlencode.aspx
G. post请求(body)
一、body数据类型
常见的post提交数据类型有四种:1.第一种:application/json:这是最常见的json格式,也是非常友好的深受小伙伴喜欢的一种,如下{"input1":"xxx","input2":"ooo","remember":false}
2.第二种:application/x-www-form-urlencoded:浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数input1=xxx&input2=ooo&remember=false
3.第三种:multipart/form-data:这一种是表单格式的,数据类型如下:------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="text"title------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png PNG ... content of chrome.png ...------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
4.第四种:text/xml:这种直接传的xml格式
examples.getStateName 41
二、json格式
1.打开博客园的登录页面,输入账号密码后抓包,查看post提交数据,点开Raw查看整个请求的原始数据
2.前面讲过post的请求多一个body部分,上图红色区域就是博客园登录接口的body部分,很明显这种格式是前面讲到的第一种json格式
3.查看json格式的树状结构,更友好,可以点开JSON菜单项

4.查看这里的json数据,很明显传了三个参数:
--input1:这个是登录的账号参数(加密过)--input2:这个是登录的密码参数(加密过)--remember:这个是登录页面的勾选是否记住密码的选项,False是不记住,True是记住
三、x-www-form-urlencoded1.登录博客园后,打开新随笔,随便写一个标题和一个正文后保存,抓包数据如下
2.如上图的这种格式,很明显就属于第二种了,这种类型的数据查看,在WebFrom里面查看了

3.上面红色框框的Query String是url里面的参数,下面红色框框的body部分就是这次post提交的body参数部分了。
四、WebFrom1.为什么登录请求的WebFrom的body部分为空呢?

2.看上图红色框框的显示:这里只支持application/x-www-form-urlencoded这种格式的body参数,也就是说json格式的,需要在JOSN这一栏查看了。
H. 接口测试(Composer)
一、Composer简介
点开右侧Composer区域,可以看到如下界面,就是测试接口的界面了
1.请求方式:点开可以勾选请求协议是get、post等
2.url地址栏:输入请求的url地址3.请求头:第三块区域可以输入请求头信息4.请求body:post请求在此区域输入body信息
5.执行:Execute按钮点击后就可以执行请求了6.http版本:可以勾选http版本7.请求历史:执行完成后会在右侧History区域生成历史记录 二、模拟get请求1.在Composer区域地址栏输入博客首页:http://www.cnblogs.com/yoyoketang/2.选择get请求,点Execute执行,请求就可以发送成功啦3.请求发送成功后,左边会话框会生成一个会话记录,可以查看抓包详情4.右侧history区域会多一个历史请求记录
5.会话框选中该记录,查看测试结果:
--选中该会话,点开Inspectors--response区域点开Raw区域--Raw查看的是HTML源码的数据
--也可以点WebView,查看返回的web页面数据
三、Json数据
1.有些post的请求参数和返回参数是Json格式的,如博客园的登录请求:https://passport.cnblogs.com/user/signin2.在登录页面手动输入账号和密码,登录成功。3.找到这个登录成功的会话,查看json数据如下图:
四、模拟post请求
1.请求类型勾选post2.url地址栏输入对应的请求地址3.body区域写登录的json参数,json参数直接copy上一步抓包的数据,如下图红色区域
4.header请求头区域,可以把前面登录成功后的头部抓包的数据copy过来(注意,有些请求如果请求头为空的话,会请求失败的)

5.执行成功后查看测试结果:
--执行成功如第三所示的图,显示success=True
--执行失败如下图所示,显示message=Invalid length for a Base-64 char array or string.success=False
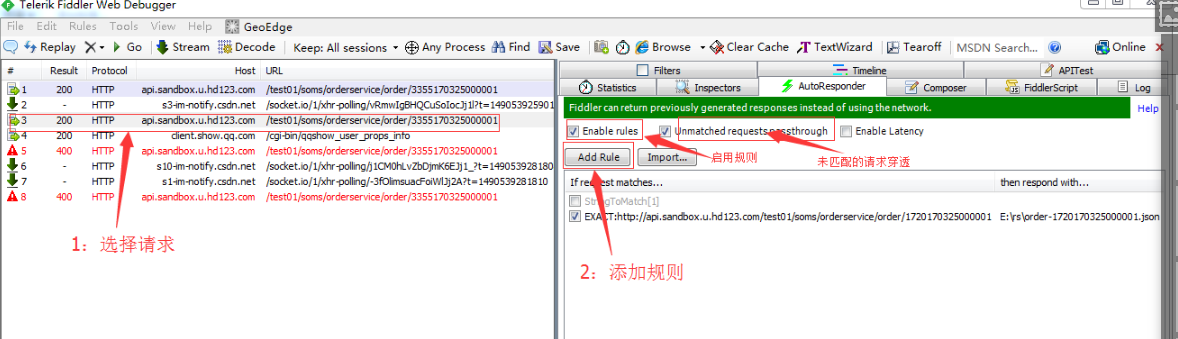
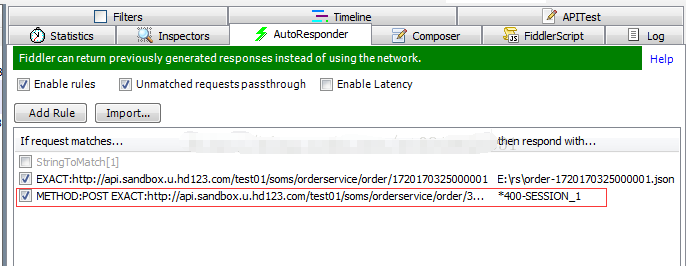
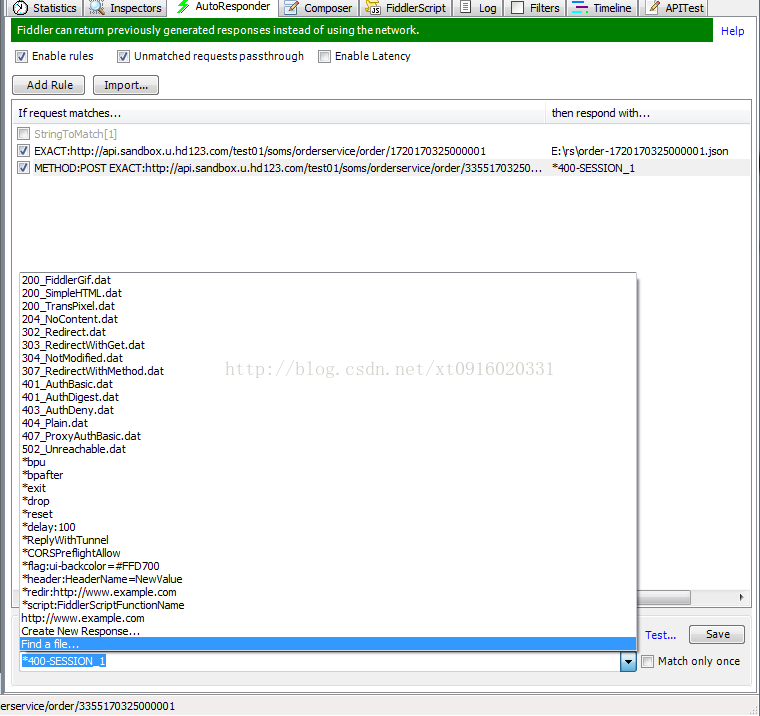
i. Fidder中的mock简单使用
mock可能很多人不理解是什么功能,但是博主只能说通过以下的讲解能够使你脑海中有个印象它有什么用,等到实际工作中真正要用的时候,这点印象能够让你回忆起曾经有过那么一篇文章写过。所以希望大家能够理解最好,不能够理解有个印象即可,不强求理解。
1. mock的作用
开发或者测试接口中,经常遇到调试过程中对接系统接口无法联调或者后台未开发完成等情况。这时,我们就需要用一个mock server来为本地环境的请求响应数据。
2. Mock假数据